
category
type
status
date
slug
summary
tags
password
Property
Jun 29, 2023 08:28 AM
icon
所有权和借用
todo
泛型
- 在方法中使用泛型
HashMap
- 使用自定义哈希函数
目前,HashMap使用的哈希函数是SipHash,它的性能不是很高,但是安全性很高。SipHash在中等大小的Key上,性能相当不错,但是对于小型的Key(例如整数)或者大型Key(例如字符串)来说,性能还是不够好。若你需要极致性能,例如实现算法,可以考虑这个库:ahash。
- 更新HashMap中对应的值
- HashMap的所有权规则和Rust其他类型一致
- 若类型实现Copy特征,该类型会被复制进HashMap,因此无所谓所有权
- 若没有实现Copy特征,所有权将会被转移到HashMap中
若要将引用类型放入HashMap中,则必须要保证该引用的生命周期至少跟HashMap活的一样久
- 使用迭代器创建HashMap
Attribute And Macro
- #[derive(Debug)]
自定义结构体要格式化输出的则必须使用
{:?}和#[derive(Debug)]。由于基本类型中实现了Display和Debug特征,故可以直接使用{}进行格式化输出。当结构体过大,且想要更容易阅读的输出格式使可以使用
{:#?}来代替{:?}- dbg!宏(macro)
它会拿走表达式的所有权,然后打印出相应的文件名、行号等debug信息和表达式的求值结果。
最后它还会返回表达式的所有权- format!:字符串格式化
流程控制
- for语句必须使用集合的引用形式,除非你不想在后续代码中继续使用该集合(如果不使用集合的引用,集合的所有权就会move到for语句块中,后续将无法使用该集合。
- 如果要在循环中修改集合的元素则使用可变引用
对应实现了Copy 特征的数组,不使用引用时,会自动拷贝,而不是进行所有权move,因此循环之后仍然可以使用对应数组。
- 使用总结
使用方法 | 等价使用方式 | 所有权 |
for item in collection | for item in IntoIterator::into_iter(collection) | 转移所有权 |
for item in &collection | for item in collection.iter() | 不可变借用 |
for item in &mut collection | for item in collection.iter_mut() | 可变借用 |
- 想在循环中获取元素索引
- 两种循环方式优劣对比
- 性能:第一种使用方式中
collection[index]的索引访问,会因为边界检查(Bounds Checking)导致运行时的性能损耗 —— Rust 会检查并确认index是否落在集合内,但是第二种直接迭代的方式就不会触发这种检查,因为编译器会在编译时就完成分析并证明这种访问是合法的 - 安全:第一种方式里对
collection的索引访问是非连续的,存在一定可能性在两次访问之间,collection发生了变化,导致脏数据产生。而第二种直接迭代的方式是连续访问,因此不存在这种风险(这里是因为所有权吗?是的话可能要强调一下)
以下代码,使用了两种循环方式:
第一种方式是循环索引,然后通过索引下标去访问集合,第二种方式是直接循环集合中的元素,优劣如下:
trait
- 特征定义了一组可以被共享的行为,只要实现了特征,就可以使用这组行为。类似Golang中的
interface中定义不同方法的签名集合,如果要实现该interface就必须要实现其中所有包括的方法。
- 特征可以用作函数参数。如果golang中,实现了interface类型中定义的所有方法就相当于实现了这个interface,也可以用作函数的参数。
- 特征约束(trait bound)
impl Trait时是一种语法糖,完整的书写格式如下:- 多重约束
- Where约束
当特征约束变得很多是,函数的签名将会变得很复杂:
- 使用特征约束有条件地实现方法或特征
- 函数中返回
impl trait,但是有限制,只能有一个具体类型 - correct
- error
- 通过derive派生特征
#[derive(Debug)]表示给一个结构体派生Debug特征,这样这个结构体就可以使用println!(”{:?}”, s)的形式进行打印改结构体对象了#[derive(Copy)],改该标记被标记到一个类型上时,可以让这个类型自动实现Copy特征,进而可以调用copy方法,进行自我复制。
- 类型转换特征TryInto
- 特征对象的创建:可以通过
&dny引用或者Box<T>智能指针的方式来创建特征对象。
特征对象的动态分发
回忆一下泛型章节我们提到过的,泛型是在编译期完成处理的:编译器会为每一个泛型参数对应的具体类型生成一份代码,这种方式是静态分发(static dispatch),因为是在编译期完成的,对于运行期性能完全没有任何影响。
与静态分发相对应的是动态分发(dynamic dispatch),在这种情况下,直到运行时,才能确定需要调用什么方法。之前代码中的关键字
dyn 正是在强调这一“动态”的特点。当使用特征对象时,Rust 必须使用动态分发。编译器无法知晓所有可能用于特征对象代码的类型,所以它也不知道应该调用哪个类型的哪个方法实现。为此,Rust 在运行时使用特征对象中的指针来知晓需要调用哪个方法。动态分发也阻止编译器有选择的内联方法代码,这会相应的禁用一些优化。
下面这张图很好的解释了静态分发
Box<T> 和动态分发 Box<dyn Trait> 的区别: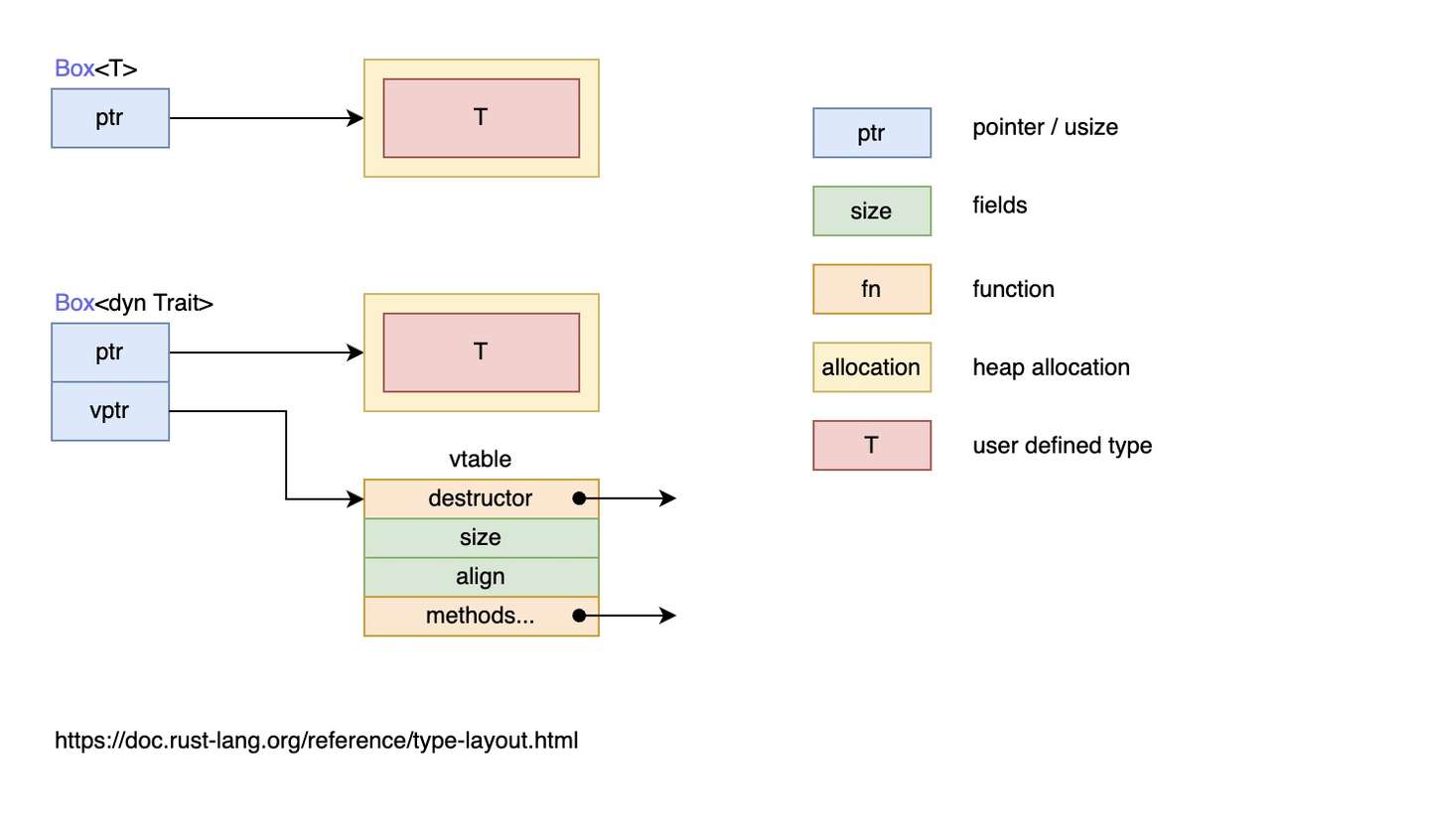
结合上文的内容和这张图可以了解:
- 特征对象大小不固定:这是因为,对于特征
Draw,类型Button可以实现特征Draw,类型SelectBox也可以实现特征Draw,因此特征没有固定大小
- 几乎总是使用特征对象的引用方式,如
&dyn Draw、Box<dyn Draw> - 虽然特征对象没有固定大小,但它的引用类型的大小是固定的,它由两个指针组成(
ptr和vptr),因此占用两个指针大小 - 一个指针
ptr指向实现了特征Draw的具体类型的实例,也就是当作特征Draw来用的类型的实例,比如类型Button的实例、类型SelectBox的实例 - 另一个指针
vptr指向一个虚表vtable,vtable中保存了类型Button或类型SelectBox的实例对于可以调用的实现于特征Draw的方法。当调用方法时,直接从vtable中找到方法并调用。之所以要使用一个vtable来保存各实例的方法,是因为实现了特征Draw的类型有多种,这些类型拥有的方法各不相同,当将这些类型的实例都当作特征Draw来使用时(此时,它们全都看作是特征Draw类型的实例),有必要区分这些实例各自有哪些方法可调用
简而言之,当类型
Button 实现了特征 Draw 时,类型 Button 的实例对象 btn 可以当作特征 Draw 的特征对象类型来使用,btn 中保存了作为特征对象的数据指针(指向类型 Button 的实例数据)和行为指针(指向 vtable)。一定要注意,此时的
btn 是 Draw 的特征对象的实例,而不再是具体类型 Button 的实例,而且 btn 的 vtable 只包含了实现自特征 Draw 的那些方法(比如 draw),因此 btn 只能调用实现于特征 Draw 的 draw 方法,而不能调用类型 Button 本身实现的方法和类型 Button 实现于其他特征的方法。也就是说,btn 是哪个特征对象的实例,它的 vtable 中就包含了该特征的方法。- self和Self
- 在 Rust 中,有两个
self和Self,self指代当前的实例对象,Self代特征或者方法类型的别名
特征对象的限制
不是所有特征都能拥有特征对象,只有对象安全的特征才行。当一个特征的所有方法都有如下属性时,它的对象才是安全的:
- 方法的返回类型不能是
Self
- 方法没有任何泛型参数
Box<T> 智能指针
- 堆、栈性能比较
- 小型数据,在栈上的分配性能和读取性能都要比堆上高
- 中型数据,栈上分配性能高,但是读取性能和堆上并无区别,因为无法利用寄存器或 CPU 高速缓存,最终还是要经过一次内存寻址
- 大型数据,只建议在堆上分配和使用
- 使用Box<T>将数据存储在堆上
println!可以正常打印出a的值,是因为它隐式地调用了Deref对智能指针a进行了解引用- 最后一行代码
let b = a + 1报错,是因为在表达式中,我们无法自动隐式地执行Deref解引用操作,你需要使用*操作符let b = *a + 1,来显式的进行解引用 a持有的智能指针将在作用域结束(main函数结束)时,被释放掉,这是因为Box<T>实现了Drop特征
如果一个变量拥有数值
let a = 3,那么变量a必然是存储在栈上的,可以通过使用Box<T>将a的值存储在堆上- 避免栈上数据的拷贝
当栈上数据转移所有权时,实际上是把数据拷贝了一份,最终新旧变量各自拥有不同的数据,因此所有权并未转移。
而堆上则不然,底层数据并不会被拷贝,转移所有权仅仅是复制一份栈中的指针,再将新的指针赋予新的变量,然后让拥有旧指针的变量失效,最终完成了所有权的转移:
从以上代码,可以清晰看出大块的数据为何应该放入堆中,此时
Box 就成为了我们最好的帮手。- Box<T>实现特征对象
Deref和Drop
*背后的原理
当我们对智能指针
Box进行解引用是,实际上Rust为我们调用了以下的方法:*不会无限递归替换,从而产生形如:((y.deref()).deref())的怪物
Deref
copy、copied、unwrap、unwrap_or、unwrap_or_else的作用和区别
copy 和 copied最大区别是一个是Some()一个是Ok()
unwrap()就是要么给我结果要么panic,unwrap_or()给你一个default值,前者不推荐使用
unwrap_or_else()你可以写一个闭包函数
生命周期
生命周期,简而言之就是引用的有效作用域。在大多数时候,我们无需手动声明生命周期,因为编译器可以自动进行推导。 在存在多个引用时,编译器有时会无法自动推导生命周期,此时就需要我们手动去标注,通过为参数标注合适的生命周期来帮助编译器进行借用检查的分析。 在通过函数签名指定生命周期参数是,我们并没有改变传入引用或者返回引用的真实生命周期,而是告诉编译器当不满足此约束条件是,就拒绝编译通过。 函数或者方法中,参数的生命周期被称为输入生命周期,返回值的生命周期被称为输出生命周期
生命周期的主要作用是避免悬垂引用,它会导致程序引用了本不该引用的数据:
这段代码有几点值得注意:
let r;的声明方式貌似存在使用null的风险,实际上,当我们不初始化它就使用时,编译器会给予报错
r引用了内部花括号中的x变量,但是x会在内部花括号}处被释放,因此回到外部花括号后,r会引用一个无效的x
此处
r 就是一个悬垂指针,它引用了提前被释放的变量 x,可以预料到,这段代码会报错- 例子
- 错误方法
编译器报错,因为longes返回的最大声明周期的大小和string2相同,故无法在括号结束后继续通过println!输出result的值【即使string1比string2长】
- 结构体生命周期
- 对于一个函数,如果它的返回值是一个引用类型,那么该引用只有两种情况:
- 从参数中获取
- 从函数体内部新创建的变量获取:【该种方式会出现悬垂引用,编译不通过】
- 不用显式标注生命周期的三种情况
- 每一个引用参数都会获得独自的生命周期
- 若只有一个输入生命周期(函数参数中只有一个引用类型),那么该生命周期会被赋给所有的输出生命周期,也就是所有返回值的生命周期都等于该输入生命周期
- 若存在多个输入生命周期,且其中一个是
&self或&mut self,则&self的生命周期被赋给所有的输出生命周期
例如一个引用参数的函数就有一个生命周期标注:
fn foo<'a>(x: &'a i32),两个引用参数的有两个生命周期标注:fn foo<'a, 'b>(x: &'a i32, y: &'b i32), 依此类推。例如函数
fn foo(x: &i32) -> &i32,x 参数的生命周期会被自动赋给返回值 &i32,因此该函数等同于 fn foo<'a>(x: &'a i32) -> &'a i32拥有
&self 形式的参数,说明该函数是一个 方法,该规则让方法的使用便利度大幅提升。'a: 'b,是生命周期约束语法,跟泛型约束非常相似,用于说明'a必须比'b活得久
- 可以把
'a和'b都在同一个地方声明(如上),或者分开声明但通过where 'a: 'b约束生命周期关系,如下:
- 静态生命周期static
- 生命周期
'static意味着能和程序活得一样久,例如字符串字面量和特征对象 - 实在遇到解决不了的生命周期标注问题,可以尝试
T: 'static,有时候它会给你奇迹
在 Rust 中有一个非常特殊的生命周期,那就是
'static,拥有该生命周期的引用可以和整个程序活得一样久。在之前我们学过字符串字面量,提到过它是被硬编码进 Rust 的二进制文件中,因此这些字符串变量全部具有
'static 的生命周期:总结下:
事实上,关于 'static, 有两种用法:&'static和T: 'static,详细内容请参见此处。
- 一个复杂例子: 泛型、特征约束
依然是熟悉的配方
longest,但是多了一段废话: ann,因为要用格式化 {} 来输出 ann,因此需要它实现 Display 特征panic
- 如果是
main线程,则程序会终止,如果是其它子线程,该线程会终止,但是不会影响main线程。因此,尽量不要在main线程中做太多任务,将这些任务交由子线程去做,就算子线程panic也不会导致整个程序的结束。
具体解析见 panic 原理剖析。
Rc、Arc
Rc和Arc通过引用计数来解决形如:可变引用不能同时出现、可变引用和非可变引用不能同时出现的相关问题
- Rc:单线程非原子引用计数
- Arc:多线程原子引用计数
Cell、RefCell
Rust 规则 | 智能指针带来的额外规则 |
一个数据只有一个所有者 | Rc/Arc让一个数据可以拥有多个所有者 |
要么多个不可变借用,要么一个可变借用 | RefCell实现编译期可变、不可变引用共存 |
违背规则导致编译错误 | 违背规则导致运行时 panic |
Cell只适用于Copy类型,用于提供值,而RefCell用于提供引用
Cell不会panic,而RefCell会
并发编程
- 作者:axiszql
- 链接:https://axiszql.com/article/newlife-my-rust-note
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。